Digital Foundry: the complete Xbox One architects interview
The whole story.


So here we go - a complete transcript of Digital Foundry's discussions on the Xbox One architecture with two integral members of the team that helped create the hardware. We're looking at around an hour's worth of very dense tech talk here, much of which you will not have seen before.
But first, a little background. How did this opportunity come about? At Gamescom in August, it became clear that Microsoft was looking to adjust its stance on how it talked about its hardware from a technological perspective. Almost certainly this came about owing to an overall spec sheet that does not look too encouraging compared to the equivalent metrics being offered by Sony for the PlayStation 4, and it was clear that gamer interpretations of some of the specs didn't quite square with Microsoft's thinking over its design.
Over and above the upcoming console war though, it's clear that Xbox One has been designed with a very different philosophy in mind, with some ambitious tech powering elements such as concurrent apps and multiple virtual machines. There's a very different approach to GPU compute too - not to mention the whole balance argument. Coming out of the experience, it was clear that this was a story that the architects were passionate about and very much wanted to tell.
That said, Microsoft does have a history in sharing in-depth data on the make-up of its console architectures, and its presentation at Hot Chips 25 this year at Stanford University indicated that the design team were willing to talk in detail about the silicon to a degree beyond what Sony are willing to share - which is perhaps understandable on the PlayStation front when you have a spec sheet that essentially does most of the talking for you.
"For Microsoft, this was an opportunity to explain a design philosophy that core gamers aren't connecting with so easily."
So the question many of you are no doubt asking is, are we looking at a free-flowing technical discussion or a PR exercise? Well, let's not kid ourselves - every interview that reaches publication is some form of public relations for the interviewee and that applies equally whether we're talking to Microsoft, Sony or anybody else. Perhaps the lingering disappointment for us with our Mark Cerny interview was the fact that it quickly became evident he was not going to let us into much that he hadn't already covered elsewhere. It's also fair to say that the impressive specs, well-rounded line-up and a phenomenally well-managed PR strategy have left Sony in a very favourable position, with nothing to prove - for now, at least.
For Microsoft, things are clearly very different. It's a case of explaining a design philosophy that core gamers aren't connecting with so easily, while at the same time getting across the message that the technological prowess of a games console isn't limited just to the compute power of the GPU or the memory set-up - though ironically, in combination with the quality of the development environment, these are the very strengths that allowed Xbox 360 to dominate the early years of the current-gen console battle.
Onto the discussion then - perhaps Digital Foundry's most expansive hardware interview yet, kicking off with the requisite conference call introductions...
My name is Andrew Goossen - I'm a technical fellow at Microsoft. I was one of the architects for the Xbox One. I'm primarily involved with the software side but I've worked a lot with Nick and his team to finalise the silicon. For designing a good, well-balanced console you really need to be considering all the aspects of software and hardware. It's really about combining the two to achieve a good balance in terms of performance. We're actually very pleased to have the opportunity to talk with you about the design. There's a lot of misinformation out there and a lot of people who don't get it. We're actually extremely proud of our design. We think we have very good balance, very good performance, we have a product which can handle things other than just raw ALU. There's also quite a number of other design aspects and requirements that we put in around things like latency, steady frame-rates and that the titles aren't interrupted by the system and other things like that. You'll see this very much as a pervasive ongoing theme in our system design.
I'm Nick Baker, I manage the hardware architecture team. We've worked on pretty much all instances of the Xbox. My team is really responsible for looking at all the available technologies. We're constantly looking to see where graphics are going - we work a lot with Andrew and the DirectX team in terms of understanding that. We have a good relationship with a lot of other companies in the hardware industry and really the organisation looks to us to formulate the hardware, what technology are going to be appropriate for any given point in time. When we start looking at what's the next console going to look like, we're always on top of the roadmap, understanding where that is and how appropriate to combine with game developers and software technology and get that all together. I manage the team. You may have seen John Sell who presented at Hot Chips, he's one of my organisation. Going back even further I presented at Hot Chips with Jeff Andrews in 2005 on the architecture of the Xbox 360. We've been doing this for a little while - as has Andrew. Andrew said it pretty well: we really wanted to build a high-performance, power-efficient box. We really wanted to make it relevant to the modern living room. Talking about AV, we're the only ones to put in an AV in and out to make it media hardware that's the centre of your entertainment.
"We really wanted to build a high-performance, power-efficient box. We really wanted to make it relevant to the modern living room."

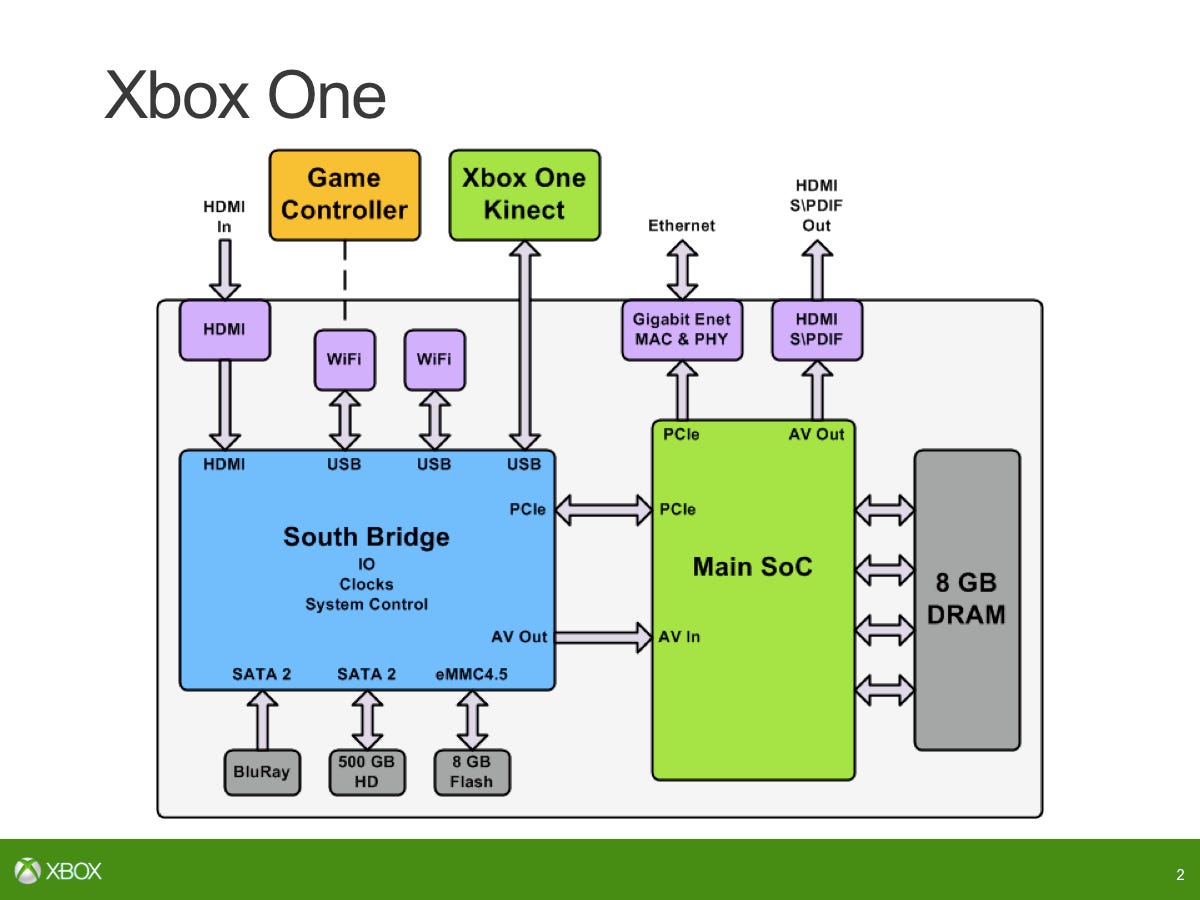
It's hard to pick out a few aspects we can talk about here in a small amount of time. I think one of the key points... We took a few gambles last time around and one of them was to go with a multi-processor approach rather than go with a small number of high IPC [instructions per clock] power-hungry CPU cores. We took the approach of going more parallel with cores more optimised for power/performance area. That worked out pretty well... There are a few things we realised like off-loading audio, we had to tackle that, hence the investment in the audio block. We wanted to have a single chip from the start and get everything as close to memory as possible. Both the CPU and GPU - give everything low latency and high bandwidth - that was the key mantra.
Some obvious things we had to deal with - a new configuration of memory, we couldn't really pass pointers from CPU to GPU so we really wanted to address that, heading towards GPGPU, compute shaders. Compression, we invested a lot in that so hence some of the Move Engines, which deal with a lot of the compression there... A lot of focus on GPU capabilities in terms of how that worked. And then really how do you allow the system services to grow over time without impacting title compatibility. The first title of the generation - how do you ensure that that works on the last console ever built while we value-enhance the system-side capabilities.
There was lot of bitty stuff to do. We had to make sure that the whole system was capable of virtualisation, making sure everything had page tables, the IO had everything associated with them. Virtualised interrupts.... It's a case of making sure the IP we integrated into the chip played well within the system. Andrew?
I'll jump in on that one. Like Nick said there's a bunch of engineering that had to be done around the hardware but the software has also been a key aspect in the virtualisation. We had a number of requirements on the software side which go back to the hardware. To answer your question Richard, from the very beginning the virtualisation concept drove an awful lot of our design. We knew from the very beginning that we did want to have this notion of this rich environment that could be running concurrently with the title. It was very important for us based on what we learned with the Xbox 360 that we go and construct this system that would disturb the title - the game - in the least bit possible and so to give as varnished an experience on the game side as possible but also to innovate on either side of that virtual machine boundary.
We can do things like update the operating system on the system side of things while retaining very good compatibility with the portion running on the titles, so we're not breaking back-compat with titles because titles have their own entire operating system that ships with the game. Conversely it also allows us to innovate to a great extent on the title side as well. With the architecture, from SDK to SDK release as an example we can completely rewrite our operating system memory manager for both the CPU and the GPU, which is not something you can do without virtualisation. It drove a number of key areas... Nick talked about the page tables. Some of the new things we have done - the GPU does have two layers of page tables for virtualisation. I think this is actually the first big consumer application of a GPU that's running virtualised. We wanted virtualisation to have that isolation, that performance. But we could not go and impact performance on the title.
We constructed virtualisation in such a way that it doesn't have any overhead cost for graphics other than for interrupts. We've contrived to do everything we can to avoid interrupts... We only do two per frame. We had to make significant changes in the hardware and the software to accomplish this. We have hardware overlays where we give two layers to the title and one layer to the system and the title can render completely asynchronously and have them presented completely asynchronously to what's going on system-side.
System-side it's all integrated with the Windows desktop manager but the title can be updating even if there's a glitch - like the scheduler on the Windows system side going slower... we did an awful lot of work on the virtualisation aspect to drive that and you'll also find that running multiple system drove a lot of our other systems. We knew we wanted to be 8GB and that drove a lot of the design around our memory system as well.
"With the architecture, from SDK to SDK release as an example we can completely rewrite our operating system memory manager for both the CPU and the GPU, which is not something you can do without virtualisation."
Yeah I think that was a pretty early decision we made when we were looking at the kind of experiences that we wanted to run concurrently with the title. And how much memory we would need there. That would have been a really early decision for us.
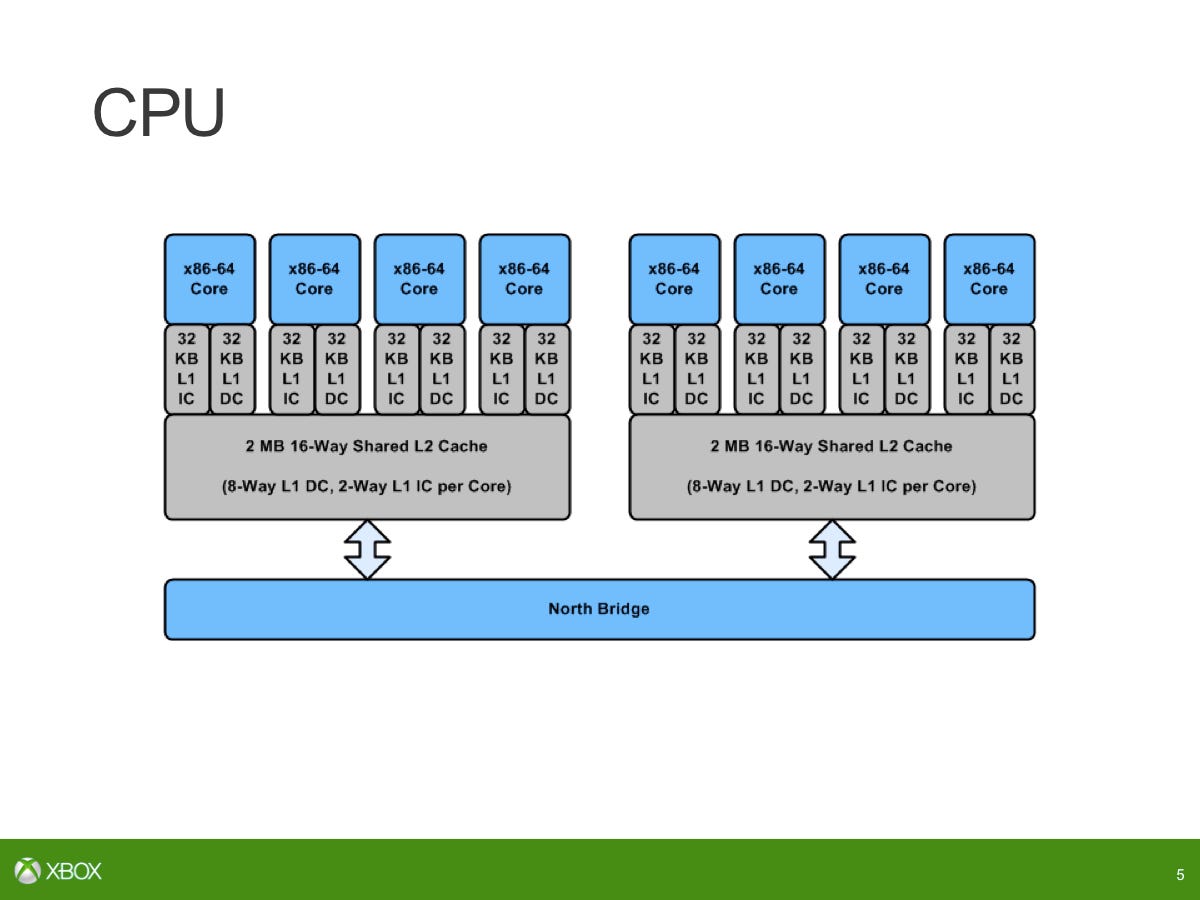
The extra power and area associated with getting that additional IPC boost going from Jaguar to Piledriver... It's not the right decision to make for a console. Being able to hit the sweet spot of power/performance per area and make it a more parallel problem. That's what it's all about. How we're partitioning cores between the title and the operating system works out as well in that respect.
There had not been a two-cluster Jaguar configuration before Xbox One so there were things that had to be done in order to make that work. We wanted higher coherency between the GPU and the CPU so that was something that needed to be done, that touched a lot of the fabric around the CPU and then looking at how the Jaguar core implemented virtualisation, doing some tweaks there - but nothing fundamental to the ISA or adding instructions or adding instructions like that.
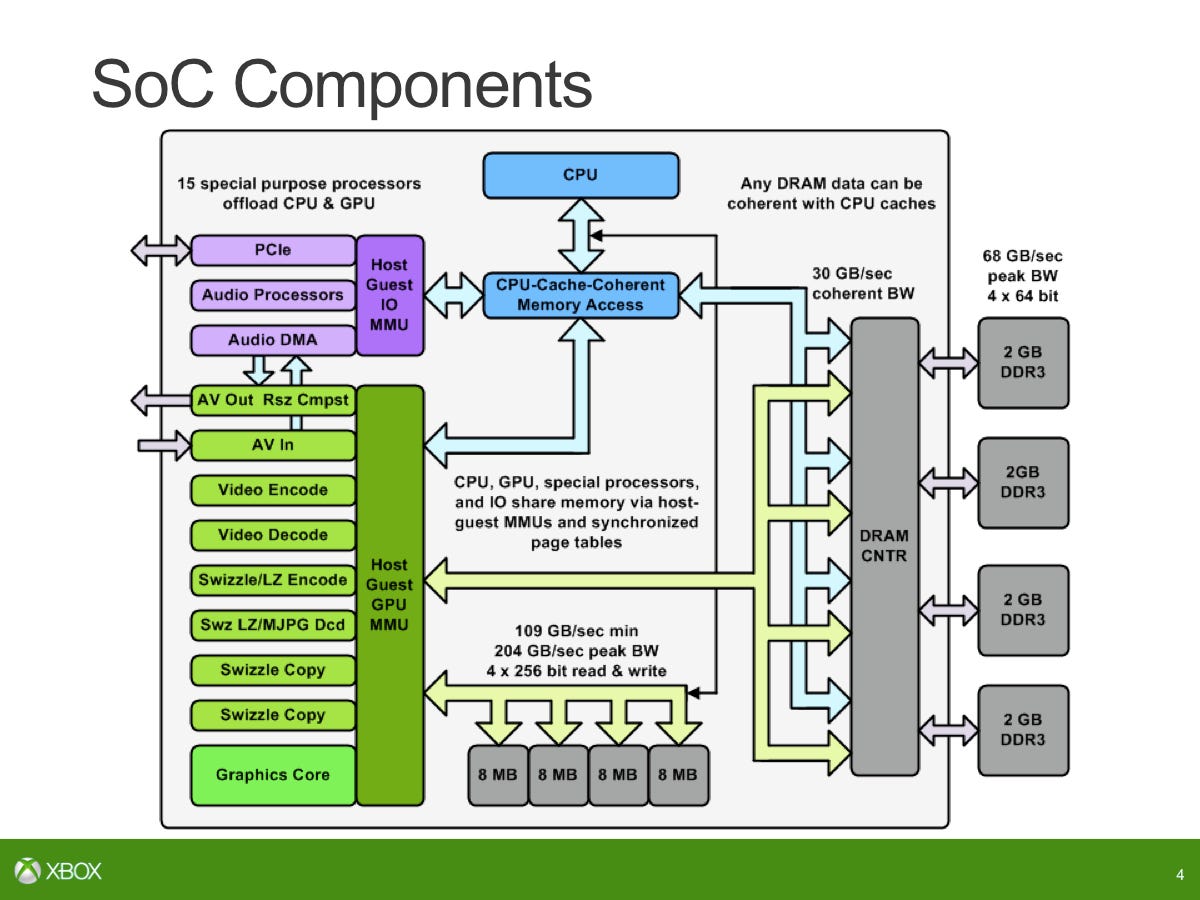
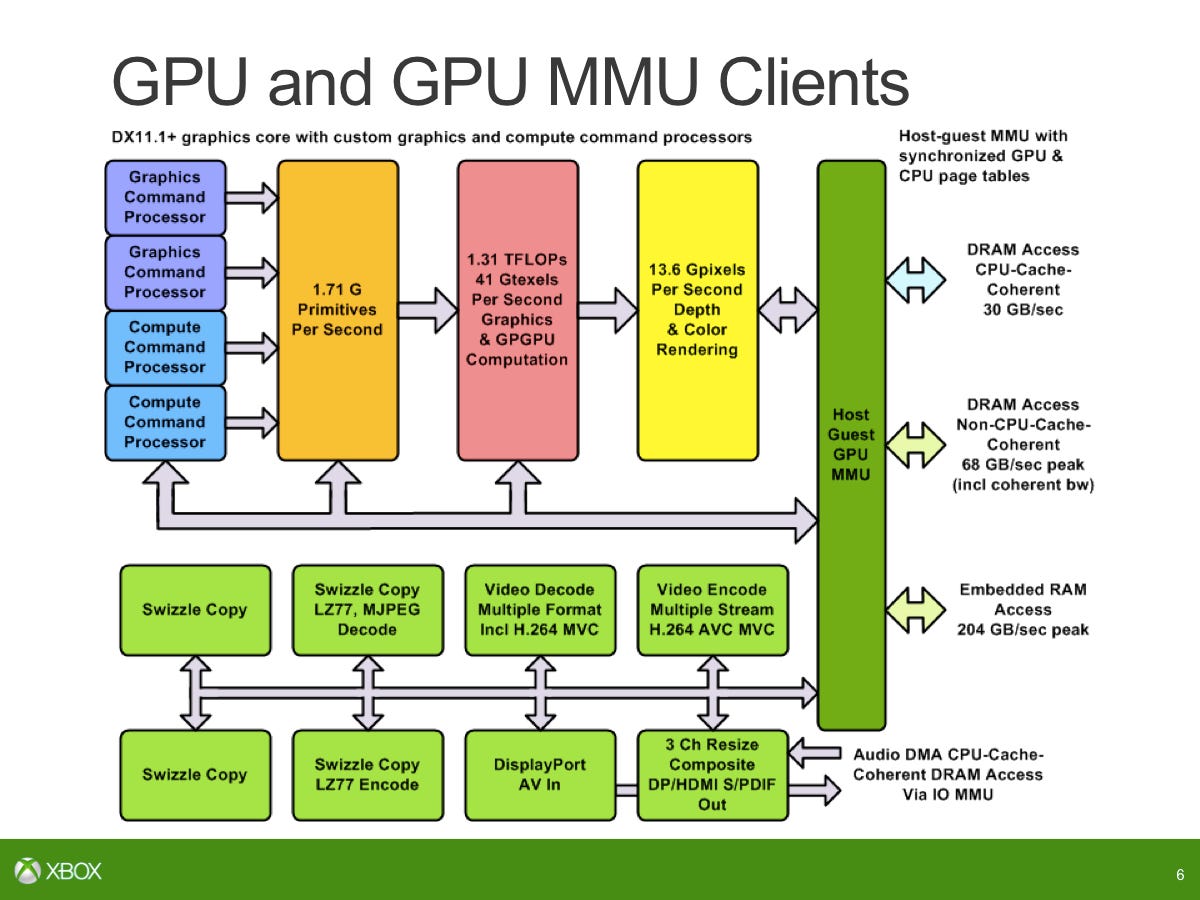
On the SoC, there are many parallel engines - some of those are more like CPU cores or DSP cores. How we count to 15: [we have] eight inside the audio block, four move engines, one video encode, one video decode and one video compositor/resizer.
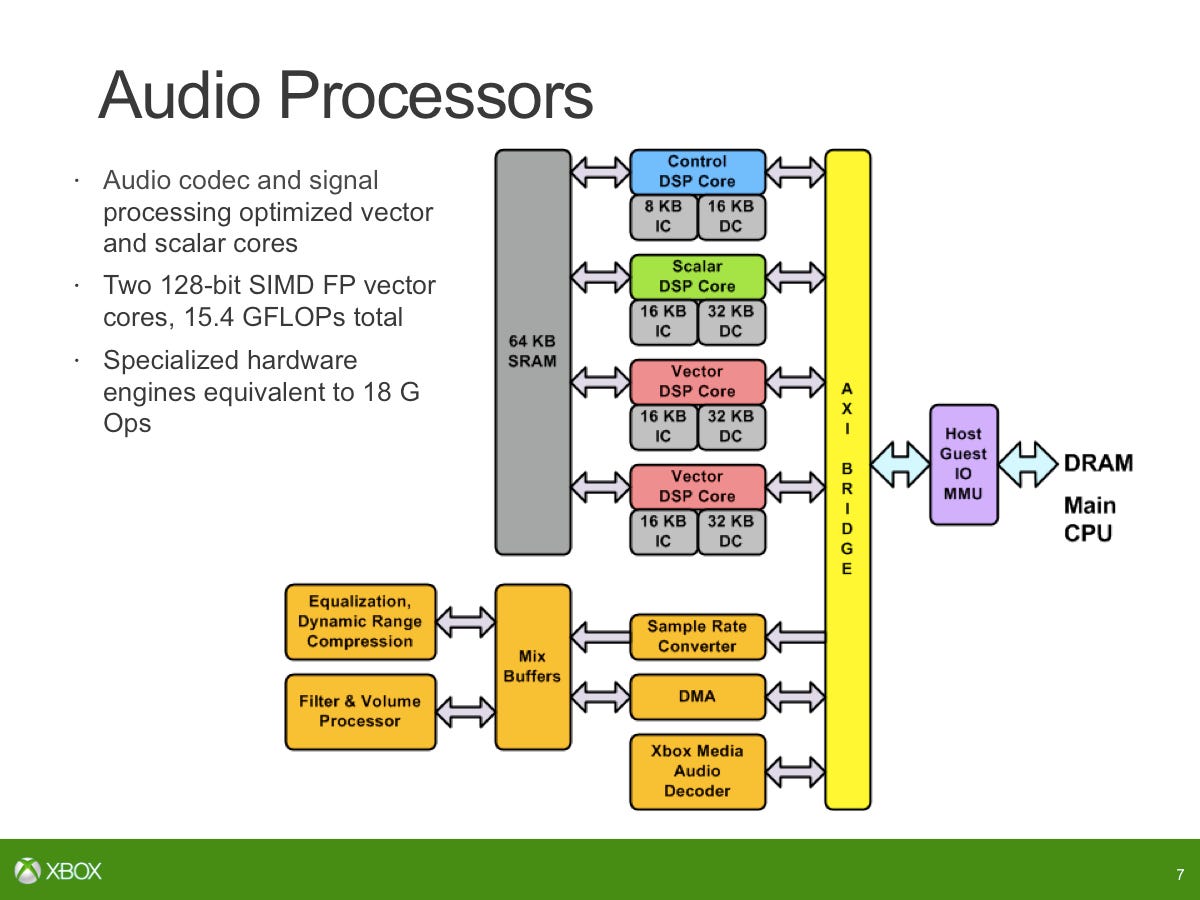
The audio block was completely unique. That was designed by us in-house. It's based on four tensilica DSP cores and several programmable processing engines. We break it up as one core running control, two cores running a lot of vector code for speech and one for general purpose DSP. We couple with that sample rate conversion, filtering, mixing, equalisation, dynamic range compensation then also the XMA audio block. The goal was to run 512 simultaneous voices for game audio as well as being able to do speech pre-processing for Kinect.
Yeah, Andrew can talk about the middleware point but some of these things are just reserved for the system to do things like Kinect processing. These are system services we provide. Part of that processing is dedicated to the Kinect.
So a lot of what we've designed for the system and the system reservation is to offload a lot of the work from the title and onto the system. You have to keep in mind that this is doing a bunch of work that is actually on behalf of the title. We're taking on the voice recognition mode in our system reservations whereas other platforms will have that as code that developers will have to link in and pay out of from their budget. Same thing with Kinect and most of our NUI [Natural User Interface] features are provided free for the games - also the Game DVR.
Yeah, I think that's right. In terms of getting the best possible combination of performance, memory size, power, the GDDR5 takes you into a little bit of an uncomfortable place. Having ESRAM costs very little power and has the opportunity to give you very high bandwidth. You can reduce the bandwidth on external memory - that saves a lot of power consumption as well and the commodity memory is cheaper as well so you can afford more. That's really a driving force behind that. You're right, if you want a high memory capacity, relatively low power and a lot of bandwidth there are not too many ways of solving that.
"In terms of getting the best possible combination of performance, memory size, power, the GDDR5 takes you into a little bit of an uncomfortable place. Having ESRAM costs very little power and has the opportunity to give you very high bandwidth."


It's just a matter of who has the technology available to do eDRAM on a single die.
No, we wanted a single processor, like I said. If there'd been a different time frame or technology options we could maybe have had a different technology there but for the product in the timeframe, ESRAM was the best choice.
First of all, there's been some question about whether we can use ESRAM and main RAM at the same time for GPU and to point out that really you can think of the ESRAM and the DDR3 as making up eight total memory controllers, so there are four external memory controllers (which are 64-bit) which go to the DDR3 and then there are four internal memory controllers that are 256-bit that go to the ESRAM. These are all connected via a crossbar and so in fact it will be true that you can go directly, simultaneously to DRAM and ESRAM.
Over that interface, each lane - to ESRAM is 256-bit making up a total of 1024 bits and that's in each direction. 1024 bits for write will give you a max of 109GB/s and then there's separate read paths again running at peak would give you 109GB/s. What is the equivalent bandwidth of the ESRAM if you were doing the same kind of accounting that you do for external memory... With DDR3 you pretty much take the number of bits on the interface, multiply by the speed and that's how you get 68GB/s. That equivalent on ESRAM would be 218GB/s. However, just like main memory, it's rare to be able to achieve that over long periods of time so typically an external memory interface you run at 70-80 per cent efficiency.
The same discussion with ESRAM as well - the 204GB/s number that was presented at Hot Chips is taking known limitations of the logic around the ESRAM into account. You can't sustain writes for absolutely every single cycle. The writes is known to insert a bubble [a dead cycle] occasionally... One out of every eight cycles is a bubble, so that's how you get the combined 204GB/s as the raw peak that we can really achieve over the ESRAM. And then if you say what can you achieve out of an application - we've measured about 140-150GB/s for ESRAM. That's real code running. That's not some diagnostic or some simulation case or something like that. That is real code that is running at that bandwidth. You can add that to the external memory and say that that probably achieves in similar conditions 50-55GB/s and add those two together you're getting in the order of 200GB/s across the main memory and internally.
One thing I should point out is that there are four 8MB lanes. But it's not a contiguous 8MB chunk of memory within each of those lanes. Each lane, that 8MB is broken down into eight modules. This should address whether you can really have read and write bandwidth in memory simultaneously. Yes you can there are actually a lot more individual blocks that comprise the whole ESRAM so you can talk to those in parallel and of course if you're hitting the same area over and over and over again, you don't get to spread out your bandwidth and so that's why one of the reasons why in real testing you get 140-150GB/s rather than the peak 204GB/s is that it's not just four chunks of 8MB memory. It's a lot more complicated than that and depending on how the pattern you get to use those simultaneously. That's what lets you do read and writes simultaneously. You do get to add the read and write bandwidth as well adding the read and write bandwidth on to the main memory. That's just one of the misconceptions we wanted to clean up.
If you're only doing a read you're capped at 109GB/s, if you're only doing a write you're capped at 109GB/s. To get over that you need to have a mix of the reads and the writes but when you are going to look at the things that are typically in the ESRAM, such as your render targets and your depth buffers, intrinsically they have a lot of read-modified writes going on in the blends and the depth buffer updates. Those are the natural things to stick in the ESRAM and the natural things to take advantage of the concurrent read/writes.
Yes. That's been measured.
"The Xbox One has a conservative 10 per cent time-sliced reservation on the GPU for system processing. This is used both for the GPGPU processing for Kinect and for the rendering of concurrent system content such as snap mode."

When we started, we wrote a spec. Before we really went into any implementation details, we had to give developers something to plan around before we had the silicon, before we even had it running in simulation before tape-out, and said that the minimum bandwidth we want from the ESRAM is 102GB/s. That became 109GB/s [with the GPU speed increase]. In the end, once you get into implementing this, the logic turned out that you could go much higher.
I just wanted to jump in from a software perspective. This controversy is rather surprising to me, especially when you view ESRAM as the evolution of eDRAM from the Xbox 360. No-one questions on the Xbox 360 whether we can get the eDRAM bandwidth concurrent with the bandwidth coming out of system memory. In fact, the system design required it. We had to pull over all of our vertex buffers and all of our textures out of system memory concurrent with going on with render targets, colour, depth, stencil buffers that were in eDRAM.
Of course with Xbox One we're going with a design where ESRAM has the same natural extension that we had with eDRAM on Xbox 360, to have both going concurrently. It's a nice evolution of the Xbox 360 in that we could clean up a lot of the limitations that we had with the eDRAM. The Xbox 360 was the easiest console platform to develop for, it wasn't that hard for our developers to adapt to eDRAM, but there were a number of places where we said, "Gosh, it would sure be nice if an entire render target didn't have to live in eDRAM," and so we fixed that on Xbox One where we have the ability to overflow from ESRAM into DDR3 so the ESRAM is fully integrated into our page tables and so you can kind of mix and match the ESRAM and the DDR memory as you go.
Sometimes you want to get the GPU texture out of memory and on Xbox 360 that required what's called a "resolve pass" where you had to do a copy into DDR to get the texture out - that was another limitation we removed in ESRAM, as you can now texture out of ESRAM if you want to. From my perspective it's very much an evolution and improvement - a big improvement - over the design we had with the Xbox 360. I'm kind of surprised by all this, quite frankly.
Oh, absolutely. And you can even make it so that portions of your render target that have very little overdraw... For example, if you're doing a racing game and your sky has very little overdraw, you could stick those subsets of your resources into DDR to improve ESRAM utilisation. On the GPU we added some compressed render target formats like our 6e4 [six bit mantissa and four bits exponent per component] and 7e3 HDR float formats [where the 6e4 formats] that were very, very popular on Xbox 360, which instead of doing a 16-bit float per component 64pp render target, you can do the equivalent with us using 32 bits - so we did a lot of focus on really maximizing efficiency and utilisation of that ESRAM.
We do but it's very slow.
You're right. GPUs are less latency sensitive. We've not really made any statements about latency.
To a large extent we inherited a lot of DX11 design. When we went with AMD, that was a baseline requirement. When we started off the project, AMD already had a very nice DX11 design. The API on top, yeah I think we'll see a big benefit. We've been doing a lot of work to remove a lot of the overhead in terms of the implementation and for a console we can go and make it so that when you call a D3D API it writes directly to the command buffer to update the GPU registers right there in that API function without making any other function calls. There's not layers and layers of software. We did a lot of work in that respect.
We also took the opportunity to go and highly customise the command processor on the GPU. Again concentrating on CPU performance... The command processor block's interface is a very key component in making the CPU overhead of graphics quite efficient. We know the AMD architecture pretty well - we had AMD graphics on the Xbox 360 and there were a number of features we used there. We had features like pre-compiled command buffers where developers would go and pre-build a lot of their states at the object level where they would [simply] say, "run this". We implemented it on Xbox 360 and had a whole lot of ideas on how to make that more efficient [and with] a cleaner API, so we took that opportunity with Xbox One and with our customised command processor we've created extensions on top of D3D which fit very nicely into the D3D model and this is something that we'd like to integrate back into mainline 3D on the PC too - this small, very low-level, very efficient object-orientated submission of your draw [and state] commands.
"The biggest thing in terms of the number of compute units, that's been something that's been very easy to focus on. It's like, hey, let's count up the number of CUs, count up the gigaflops and declare the winner based on that."

Just like our friends we're based on the Sea Islands family. We've made quite a number of changes in different parts of the areas. The biggest thing in terms of the number of compute units, that's been something that's been very easy to focus on. It's like, hey, let's count up the number of CUs, count up the gigaflops and declare the winner based on that. My take on it is that when you buy a graphics card, do you go by the specs or do you actually run some benchmarks? Firstly though, we don't have any games out. You can't see the games. When you see the games you'll be saying, "What is the performance difference between them?" The games are the benchmarks. We've had the opportunity with the Xbox One to go and check a lot of our balance. The balance is really key to making good performance on a games console. You don't want one of your bottlenecks being the main bottleneck that slows you down.
Balance is so key to real effective performance. It's been really nice on Xbox One with Nick and his team and the system design folks have built a system where we've had the opportunity to check our balances on the system and make tweaks accordingly. Did we do a good job when we did all of our analysis a couple of years ago and simulations and guessing where games would be in terms of utilisation? Did we make the right balance decisions back then? And so raising the GPU clock is the result of going in and tweaking our balance. Every one of the Xbox One dev kits actually has 14 CUs on the silicon. Two of those CUs are reserved for redundancy in manufacturing. But we could go and do the experiment - if we were actually at 14 CUs what kind of performance benefit would we get versus 12? And if we raised the GPU clock what sort of performance advantage would we get? And we actually saw on the launch titles - we looked at a lot of titles in a lot of depth - we found that going to 14 CUs wasn't as effective as the 6.6 per cent clock upgrade that we did. Now everybody knows from the internet that going to 14 CUs should have given us almost 17 per cent more performance but in terms of actual measured games - what actually, ultimately counts - is that it was a better engineering decision to raise the clock. There are various bottlenecks you have in the pipeline that [can] cause you not to get the performance you want [if your design is out of balance].
Increasing the frequency impacts the whole of the GPU whereas adding CUs beefs up shaders and ALU.
Right. By fixing the clock, not only do we increase our ALU performance, we also increase our vertex rate, we increase our pixel rate and ironically increase our ESRAM bandwidth. But we also increase the performance in areas surrounding bottlenecks like the drawcalls flowing through the pipeline, the performance of reading GPRs out of the GPR pool, etc. GPUs are giantly complex. There's gazillions of areas in the pipeline that can be your bottleneck in addition to just ALU and fetch performance.
If you go to VGleaks, they had some internal docs from our competition. Sony was actually agreeing with us. They said that their system was balanced for 14 CUs. They used that term: balance. Balance is so important in terms of your actual efficient design. Their additional four CUs are very beneficial for their additional GPGPU work. We've actually taken a very different tack on that. The experiments we did showed that we had headroom on CUs as well. In terms of balance, we did index more in terms of CUs than needed so we have CU overhead. There is room for our titles to grow over time in terms of CU utilisation, but getting back to us versus them, they're betting that the additional CUs are going to be very beneficial for GPGPU workloads. Whereas we've said that we find it very important to have bandwidth for the GPGPU workload and so this is one of the reasons why we've made the big bet on very high coherent read bandwidth that we have on our system.
I actually don't know how it's going to play out of our competition having more CUs than us for these workloads versus us having the better performing coherent memory. I will say that we do have quite a lot of experience in terms of GPGPU - the Xbox 360 Kinect, we're doing all the Exemplar processing on the GPU so GPGPU is very much a key part of our design for Xbox One. Building on that and knowing what titles want to do in the future. Something like Exemplar... Exemplar ironically doesn't need much ALU. It's much more about the latency you have in terms of memory fetch [latency hiding of the GPU], so this is kind of a natural evolution for us. It's like, OK, it's the memory system which is more important for some particular GPGPU workloads.
Yes, some parts of the frames may have been ROP-bound. However, in our more detailed analysis we've found that the portions of typical game content frames that are bound on ROP and not bound on bandwidth are generally quite small. The primary reason that the 6.6 per cent clock speed boost was a win over additional CUs was because it lifted all internal parts of the pipeline such as vertex rate, triangle rate, draw issue rate, etc.
The goal of a 'balanced' system is by definition not to be consistently bottlenecked on any one area. In general with a balanced system there should rarely be a single bottleneck over the course of any given frame - parts of the frame can be fill-rate bound, other can be ALU bound, others can be fetch bound, others can be memory bound, others can be wave occupancy bound, others can be draw-setup bound, others can be state change bound, etc. To complicate matters further, the GPU bottlenecks can change within the course of a single draw call!
The relationship between fill-rate and memory bandwidth is a good example of where balance is necessary. A high fill-rate won't help if the memory system can't sustain the bandwidth required to run at that fill rate. For example, consider a typical game scenario where the render target is 32bpp [bits per pixel] and blending is disabled, and the depth/stencil surface is 32bpp with Z enabled. That amount to 12 bytes of bandwidth needed per pixel drawn (eight bytes write, four bytes read). At our peak fill-rate of 13.65GPixels/s that adds up to 164GB/s of real bandwidth that is needed which pretty much saturates our ESRAM bandwidth. In this case, even if we had doubled the number of ROPs, the effective fill-rate would not have changed because we would be bottlenecked on bandwidth. In other words, we balanced our ROPs to our bandwidth for our target scenarios. Keep in mind that bandwidth is also needed for vertex and texture data as well, which in our case typically comes from DDR3.
If we had designed for 2D UI scenarios instead of 3D game scenarios, we might have changed this design balance. In 2D UI there is typically no Z-buffer and so the bandwidth requirements to achieve peak fill-rate are often less.
"Game developers are naturally incented to make the highest-quality visuals possible and so will choose the most appropriate trade-off between quality of each pixel vs. number of pixels for their games."




















We've chosen to let title developers make the trade-off of resolution vs. per-pixel quality in whatever way is most appropriate to their game content. A lower resolution generally means that there can be more quality per pixel. With a high-quality scaler and antialiasing and render resolutions such as 720p or '900p', some games look better with more GPU processing going to each pixel than to the number of pixels; others look better at 1080p with less GPU processing per pixel. We built Xbox One with a higher quality scaler than on Xbox 360, and added an additional display plane, to provide more freedom to developers in this area. This matter of choice was a lesson we learned from Xbox 360 where at launch we had a Technical Certification Requirement mandate that all titles had to be 720p or better with at least 2x anti-aliasing - and we later ended up eliminating that TCR as we found it was ultimately better to allow developers to make the resolution decision themselves. Game developers are naturally incented to make the highest-quality visuals possible and so will choose the most appropriate trade-off between quality of each pixel vs. number of pixels for their games.
One thing to keep in mind when looking at comparative game resolutions is that currently the Xbox One has a conservative 10 per cent time-sliced reservation on the GPU for system processing. This is used both for the GPGPU processing for Kinect and for the rendering of concurrent system content such as snap mode. The current reservation provides strong isolation between the title and the system and simplifies game development (strong isolation means that the system workloads, which are variable, won't perturb the performance of the game rendering). In the future, we plan to open up more options to developers to access this GPU reservation time while maintaining full system functionality.
To facilitate this, in addition to asynchronous compute queues, the Xbox One hardware supports two concurrent render pipes. The two render pipes can allow the hardware to render title content at high priority while concurrently rendering system content at low priority. The GPU hardware scheduler is designed to maximise throughput and automatically fills "holes" in the high-priority processing. This can allow the system rendering to make use of the ROPs for fill, for example, while the title is simultaneously doing synchronous compute operations on the Compute Units.
Our philosophy is that ALU is really, really important going forward but like I said we did take a different tack on things. Again, on Xbox One our Kinect workloads are running on the GPU with asynchronous compute for all of our GPGPU workloads and we have all the requirements for efficient GPGPU in terms of fast coherent memory, we have our operating system - that takes us back to our system design. Our memory manager on game title side is completely rewritten. We did that to ensure that our virtual addressing for the CPU and GPU are actually the same when you're on that side. Keeping the virtual addresses the same for both CPU and GPU allows the GPU and CPU to share pointers. For example, a shared virtual address space along with coherent memory along with eliminating demand paging means the GPU can directly traverse CPU data structures such as linked lists.
On the system side we're running in a complete generic Windows memory manager but on the game side we don't have to worry about back-compat or any of these nasty issues. It's very easy for us to rewrite the memory manager and so we've got coherent memory, the same virtual addressing between the two, we have synchronisation mechanisms to coordinate between the CPU and GPU that we can run on there. I mean, we invented DirectCompute - and then we've also got things like AMP that we're making big investments on for Xbox One to actually make use of the GPU hardware and the GPGPU workloads.
The other thing I will point out is that also on the internet I see people adding up the number of ALUs and the CPU and adding that onto the GPU and saying, "Ah, you know, Microsoft's CPU boost doesn't make much of a difference." But there still are quite a number of workloads that do not run efficiently on GPGPU. You need to have data parallel workloads to run efficiently on the GPU. The GPU nowadays can run non-data parallel workloads but you're throwing away massive amounts of performance. And for us, getting back to the balance and being able to go back and tweak our performance with the overhead in the margin that we had in the thermals and the silicon design, it kind of enabled us to go back and look at things. We looked at our launch titles and saw that - hey we didn't make the balance between CPU and GPU in terms of our launch titles - we probably under-tweaked it when we designed it two or three years ago. And so it was very beneficial to go back and do that clock raise on the CPU because that's a big benefit to your workloads that can't be running data parallel.
"The biggest source of your frame-rate drops actually comes from the CPU, not the GPU... In providing what looks like a very little boost, it's actually a very significant win for us in making sure that we get the steady frame-rates on our console."

The number of asynchronous compute queues provided by the ACEs doesn't affect the amount of bandwidth or number of effective FLOPs or any other performance metrics of the GPU. Rather, it dictates the number of simultaneous hardware "contexts" that the GPU's hardware scheduler can operate on any one time. You can think of these as analogous to CPU software threads - they are logical threads of execution that share the GPU hardware. Having more of them doesn't necessarily improve the actual throughput of the system - indeed, just like a program running on the CPU, too many concurrent threads can make aggregate effective performance worse due to thrashing. We believe that the 16 queues afforded by our two ACEs are quite sufficient.
Another very important thing for us in terms of design on the system was to ensure that our game had smooth frame-rates. Interestingly, the biggest source of your frame-rate drops actually comes from the CPU, not the GPU. Adding the margin on the CPU... we actually had titles that were losing frames largely because they were CPU-bound in terms of their core threads. In providing what looks like a very little boost, it's actually a very significant win for us in making sure that we get the steady frame-rates on our console. And so that was a key design goal of ours - and we've got a lot of CPU offload going on.
We've got the SHAPE, the more efficient command processor [relative to the standard design], we've got the clock boost - it's in large part actually is to ensure that we've got the headroom for the frame-rates. We've done things on the GPU side as well with our hardware overlays to ensure more consistent frame-rates. We have two independent layers we can give to the titles where one can be 3D content, one can be the HUD. We have a higher quality scaler than we had on Xbox 360. What this does is that we actually allow you to change the scaler parameters on a frame-by-frame basis. I talked about CPU glitches causing frame glitches... GPU workloads tend to be more coherent frame to frame. There doesn't tend to be big spikes like you get on the CPU and so you can adapt to that.
What we're seeing in titles is adopting the notion of dynamic resolution scaling to avoid glitching frame-rate. As they start getting into an area where they're starting to hit on the margin there where they could potentially go over their frame budget, they could start dynamically scaling back on resolution and they can keep their HUD in terms of true resolution and the 3D content is squeezing. Again, from my aspect as a gamer I'd rather have a consistent frame-rate and some squeezing on the number of pixels than have those frame-rate glitches.
Yeah, again I think we under-balanced and we had that great opportunity to change that balance late in the game. The DMA Move Engines also help the GPU significantly as well. For some scenarios there, imagine you've rendered to a depth buffer there in ESRAM. And now you're switching to another depth buffer. You may want to go and pull what is now a texture into DDR so that you can texture out of it later and you're not doing tons of reads from that texture so it actually makes more sense for it to be in DDR. You can use the Move Engines to move these things asynchronously in concert with the GPU so the GPU isn't spending any time on the move. You've got the DMA engine doing it. Now the GPU can go on and immediately work on the next render target rather than simply move bits around.
From a power/efficiency standpoint as well, fixed functions are more power-friendly on fixed function units. We put data compression on there as well, so we have LZ compression/decompression and also motion JPEG decode which helps with Kinect. So there's a lot more than to the Data Move Engines than moving from one block of memory to another.
Sure. We use it as a cache system-side to improve system response and again not disturb system performance on the titles running underneath. So what it does is that it makes our boot times faster when you're not coming out of the sleep mode - if you're doing the cold boot. It caches the operating system on there. It also caches system data on there while you're actually running the titles and when you have the snap applications running concurrently. It's so that we're not going and hitting the hard disk at the same time that the title is. All the game data is on the HDD. We wanted to be moving that head around and not worrying about the system coming in and monkeying with the head at an inopportune time.
We knew we had headroom. We didn't know what we wanted to do with it until we had real titles to test on. How much do you increase the GPU by? How much do you increase the CPU by?
We had the headroom. It's a glorious thing to have on a console launch. Normally you're talking about having to downclock. We had a once in a lifetime opportunity to go and pick the spots where we wanted to improve the performance and it was great to have the launch titles to use as the way to drive an informed decision performance improvements we could get out of the headroom.
That's not a figure we're disclosing at this time.
But we've said on other forums as well that we have implemented multiple power levels - we scale all the way from full power down to 2.5 per cent depending on the scenario.
Yeah, getting something out is always, always a great feeling [but] my team works on multiple programs in parallel - we're constantly busy working on the architecture team.
For me, the biggest reward is to go and play the games and see that they look great and that yeah, this is why we did all that hard work. As a graphics guy it's so rewarding to see those pixels up on the screen.